

클린 아키텍처는 이제 안드로이드 진영의 많은 기업들이 선호하는(?) 아키텍처가 되었다.
내가 이 책을 읽었던 작년 이 맘 때와 비교해보면, 이제는 상당히 많은 기업들의 채용 공고 우대 사항에 들어가 있는 것을 보면서 느끼고 있다.
선호한다기보다는 구조적 이해도를 가진 개발자를 원하는 느낌이라 해야할까?
"클린 아키텍처를 실무에 적용해 본 적이 있나요?"라는 부분보다, "아키텍처의 중요성과 그에 대한 이해도를 가지고 있나요?"라는 의미에 더 가깝다고 생각한다.
오늘은 아키텍처 설계에서 SOLID 원칙의 역할과 중요성에 대해 알아보고자 한다.
Single Responsibility Principle
여러 블로그 포스팅에서는 단일 책임 원칙을 "클래스/모듈은 단 하나의 책임만 가져야 한다"고만 설명하고 있다.
하지만 이것은 단일 책임 원칙에 대한 명확한 정의가 아니며, SOLID 원칙과 클린 아키텍처의 창시자인 로버트 마틴은 이에 대해 이렇게 설명한다.
SOLID 원칙 중에서 가장 의미가 잘 전달되지 못한 원칙은 바로 단일 책임 원칙이다. 이름이 적절하지 않아서인 것 같다. 프로그래머가 이 원칙의 이름을 듣는다면 모든 모듈이 하나의 일만 해야 한다는 의미로 받아들이기 쉽다.
- 로버트 마틴
그럼 단일 책임 원칙은 정확히 어떤 의미를 가지고 있을까?
여기서 액터(Actor)라는 개념이 등장한다. 유즈케이스 다이어그램의 액터와 동일한 역할이지만, 여기서는 "변경을 요청하는 한 명 이상의 사람들"을 의미하며, 이를 적용하면 단일 책임 원칙을 이렇게 정의할 수 있다.
단일 책임 원칙
하나의 모듈은 오직 하나의 액터에 대해서만 책임을 져야 한다
print라는 행위에 대해 액터 A, B, C가 연관되어 있다면, 이를 각각의 액터에 대해서만 변경이 전파되도록 수정해야 할 것이다.
Open Closed Principle
소프트웨어 개체는 확장에는 열려 있어야 하고, 변경에는 닫혀 있어야 한다
- 버트란드 마이어
이 말은 소프트웨어 개체의 행위는 확장할 수 있어야 하지만, 이 때 개체를 수정(변경)해서는 안된다는 것이다.
만약 어떤 요구사항을 조금 확장하기 위해 소프트웨어의 많은 부분을 수정해야 한다면 그것은 잘못된 설계이며,
소프트웨어 아키텍처에 대해 공부하는 이유가 바로 이 때문이다. 소프트웨어는 soft해야한다.
잘 설계된 아키텍처라면 특정 요구사항을 확장하기 위해서 기존 코드를 수정해야하는 이상적인 양은 0이다.
이를 위해 시스템을 컴포넌트 단위로 분리하고(단일 책임 원칙), 저수준 컴포넌트에서 발생한 변경이 고수준 컴포넌트에 영향을 주지 않도록 의존성 계층구조를 설계해야 한다(의존성 역전 원칙).
안드로이드 클린 아키텍처에서는 domain-data-presentation 계층의 단방향 의존성 관계를 예시로 들 수 있다.
고수준 계층인 domain을 저수준 계층인 data-presentation 계층의 변경으로부터 보호하기 위해 의존성 역전 원칙을 적용하고, data계층을 Repository-DataSource-ApiService-Model-Mapper 등과 같은 컴포넌트로 나누고 의존성 계층 구조를 단방향화함으로써 하위 컴포넌트의 변경이 상위 컴포넌트에 영향을 주지 않도록 설계한다.
Liscop Substitution Principle
S가 T의 하위 타입(subType)일 때, T 객체를 S 객체로 치환하더라도 프로그램의 행위가 변경되지 않아야 한다
- 바바라 리스코
클래스 계층 구조를 설계할 때 서브 타입이 슈퍼 타입으로 안전하게 대체되어야 하며,
서브 클래스가 슈퍼 클래스의 기능을 확장하는 방식이 아니라 일부 기능을 변경하거나 무효하도록 구현되는 경우에는 LSP를 위배하게 된다.
그런 상황을 방지하기 위해 슈퍼 타입에서 정의한 계약을 서브 타입이 반드시 준수하도록 구현해야 한다.
이를 통해 기존 코드를 변경하지 않고도 새로운 기능을 추가하는 방식으로 확장할 수 있으며, 이는 유지 보수성의 증가로 이어진다.
Interface Segregation Principle
사용하지 않는 인터페이스에 의존해서는 안 된다.
아래 클래스 다이어그램을 예시로 들어 보자.
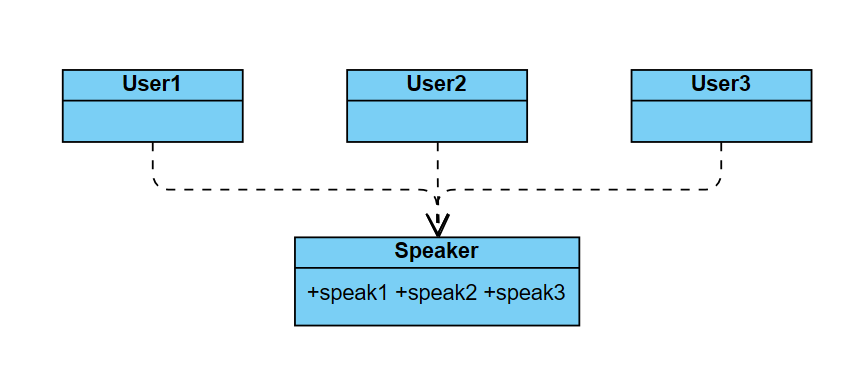
User1은 speak1만을 사용하며, speak2와 speak3을 사용하지 않음에도 Speaker 클래스에 의존하고 있으며, User2, User3 클래스도 마찬가지이다.
이런 의존 관계로 인해 Speaker 클래스에서 speak1만 변경되더라도 User2나 User3도 다시 컴파일 해야하는 상황이 발생한다. speak2나 speak3이 변경되지 않았지만 사용하지 않는 인터페이스에 의존하기 때문에 이런 문제가 발생하게 된다.
이런 경우에는 Speaker 클래스의 메서드들을 인터페이스 단위로 분리함으로써 해결할 수 있다.
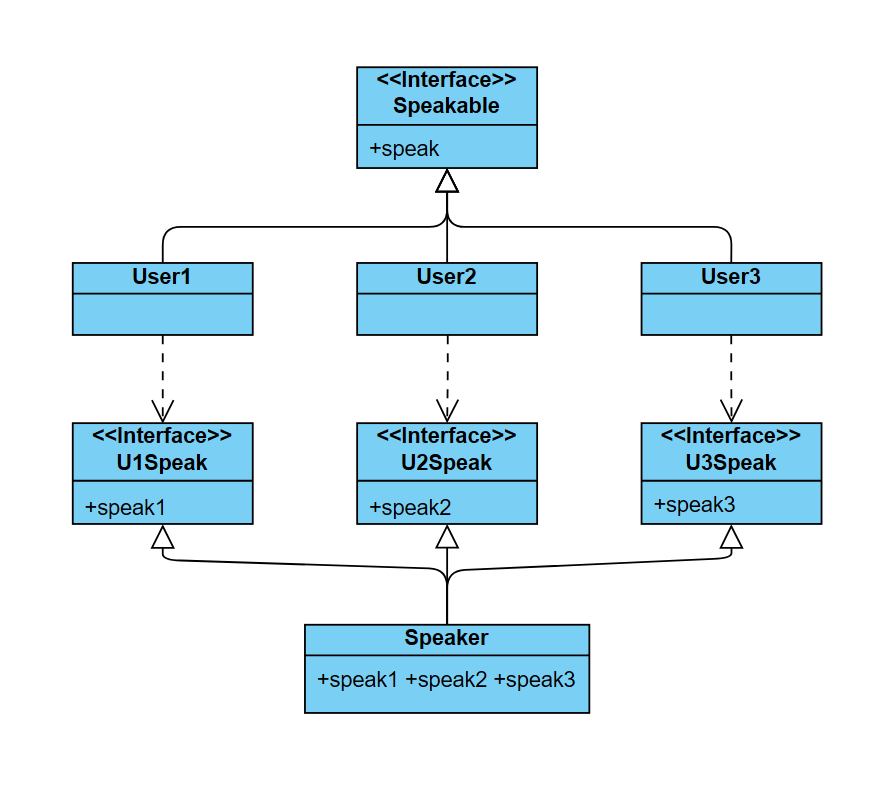
위처럼 인터페이스를 분리하면 User1은 U1Speak와 speak1에는 의존하지만 Speaker 클래스에는 의존하지 않게 된다.
따라서 Speaker 클래스에서 speak1 이외의 변경사항이 발생하는 경우에 User1을 다시 컴파일해야하는 상황이 발생하지 않는다.
위 설명은 java, kotlin과 같이 include, import 등의 타입 선언문을 사용하도록 강제하는 정적 타입 언어의 경우에만 해당된다.
Kotlin의 경우에는 import문으로 인해 클래스 간 의존성이 생기게 되고, 이로 인해 의존성을 가진 클래스가 수정되면 재컴파일이 강제된다.
하지만 이를 언어 차원에서의 원칙이라고만 보기에는 힘들다고 생각한다.
추상적인 관점에서 인터페이스 분리 원칙을 바라봤을 때, 필요 이상으로 많은 것들을 가진 요소에 의존하는 것은 위험한 일이다.
만약 A 클래스가 B 클래스의 80% 정도(예시입니다)를 사용한다고 생각해보자.
이 경우에 B 클래스의 나머지 20%는 B 클래스에 의존하는 또 다른 클래스가 사용할 것이다.
만약 B 클래스의 특정 부분이 변경될 때, A 클래스가 사용하지 않는 부분의 변경이 불필요하게 전파될 수 있음을 뜻한다.
(물론 잠재적인 위험이라 생각할 수 있지만, 굳이 그러한 리스크를 누적시키는 것은 시스템 안정성을 저하시킬 것이라 생각한다)
그렇기 때문에 B 클래스를 작은 여러 인터페이스로 분리하여 A 클래스는 자신이 실제로 사용하는 인터페이스에만 의존할 수 있도록 설계함으로써 불필요하면 변경의 전파를 방지해야 한다.
Dependency Inversion Principle
의존성 역전 원칙은 유연성을 극대화한 시스템을 위한 원칙이다.
SOLID 원칙 모두가 중요하지만, 개인적으로 클린 아키텍처에서 가장 기본적이고 핵심적인 원칙이 바로 이것이라고 생각한다.
[클린 아키텍처 계층 레벨의 DIP]
Domain-Data 계층 간에 의존성 역전 원칙을 적용하여 고수준 계층인 Domain 계층을 독립적으로 설계한다. Repository 인터페이스와 구현체로 나누며, Data 계층은 Domain 계층에 대한 의존성을 가지나 Domain 계층은 Data 계층에 대한 의존성을 가지지 않는다.
그로 인해 Data 계층의 Repository 구현체의 변경은 Domain 계층에 영향을 미칠 수 없게 된다.
클린 아키텍처는 클래스 레벨에서도 DIP를 통해 객체 생성에 강한 제약을 부여한다.
클린 아키텍처에서는 정책에 의존하되, 메커니즘에 의존해서는 안된다고 표현하고 있는데
이는 곧 추상에 의존하되 구체화된 것에 의존해서는 안된다는 의미이다.
Kotlin괴 같은 정적 타입 언어를 사용하는 입장에서는 import 구문이 오직 인터페이스/추상 클래스와 같은 추상적인 선언만을 참조해야 한다는 것으로 해석할 수 있다.
하지만 현실적으로 우리는 구체화된 여러 클래스에 의존하는 경우가 많은데, 예를 들면 String, View 등이 있다.
이들은 구체화된 클래스인데, 그럼 이 클래스에 의존하는 것은 잘못된 것일까?
여기서 의존성 역전 원칙의 본질적 의미를 잘 파악할 수 있다.
String이나 View 클래스는 구체화된 클래스이지만 변경이 발생하는 경우가 거의 없으며
발생하더라도 안정적으로 운용될 수 있으므로 개발자는 해당 클래스에 대한 변경을 신경 쓸 필요가 없다는 점이다.
이처럼 의존성 역전 원칙은 엄격하게 인터페이스/추상 클래스와 구체화된 클래스에 대한 의존 관계를 나누어 구체화된 클래스에 대한 의존을 피하라는 것이 아니다.
조금 더 추상적인 관점에서 "변동성이 적은 것"과 "변동성이 큰 것" 중에서 "변동성이 큰" 요소를 구체적인 요소로 판단하고 이에 대한 의존을 피하라는 것이다.
(하지만 이는 특수한 경우이며, 인터페이스/추상 클래스에 의존하는 경우가 대부분이다)
[세줄 요약]
인터페이스의 변경은 구현체에 전파된다.
하지만 일반적으로 구현체의 변경은 인터페이스에 전파되지 않는다!
그럼 둘 중 어느 것에 의존해야 할까? 답은 명확하다.
[핵심]
구현체가 아닌 추상화에 의존하라!
절대로 구체적인 대상에 의존해서는 안 된다.
이런 개념 공부는 분명 투자한 시간에 비해 효율적인 아웃풋이 나오는 학습은 아니라고 생각한다.
눈에 보이는 발전은 이런 추상적인 것들보다는 구체적인 요소들을 학습하는 것이 더 두드러지게 보이기 때문이다.
하지만 이런 추상적인 개념들에 대한 공부는 정말 중요하며, 장기적인 관점에서 학습의 깊이에도 큰 영향을 미칠 것이라 생각하기 때문에 같은 공부를 반복해도 다양한 관점에서 바라보려 노력하고 있다.
작년쯤 로버트 마틴의 클린 아키텍처에 대해서 작성한 글이다. 순환 참조로 조회수를 올려보자
[안드로이드] 클린 아키텍처 - (1) 개념
오늘의 주제는 로버튼 마틴 형님의 "클린 아키텍처"라는 개념이다. 많은 기업들이 해당 아키텍처 구조를 사용하고 있으며, 비즈니스 로직 덩어리가 클수록 장점이 부각되는 구조이다. 하지만 기
work2type.tistory.com
위 글을 작성할 때에는 실무 도입을 위한 공부를 했다면, 도입 이후로는 이론적인 공부를 깊이 해오고 있다.
꾸준히 공부하고 있었는데 너무 바빠서 포스팅을 남기지 못했다
앞으로도 클린 아키텍처에 대한 포스팅은 대부분이 추상적인 개념들일 것 같은데,
이게 재밌기도 하고 아키텍처는 얼마나 잘 알고 사용하느냐가 중요하다고 생각하기 때문이다.
혹시 기술 블로그들만 보고 클린 아키텍처를 공부하는 중인 사람이라면, 반드시 책을 사서 읽어보길 바란다.
아키텍처를 고안한 사람의 의도와 구조적 개선의 중요성을 제대로 느낄 수 있을 것이다.
'개발' 카테고리의 다른 글
| RxJava를 알아보자 (0) | 2022.10.12 |
|---|---|
| 레거시에 대하여 (0) | 2022.07.13 |