

💡DI 패턴을 사용하는 이유
안드로이드 진영에서 DI 패턴은 필수적으로 사용되는 디자인 패턴 중 하나이다.
여기서 개발자들은 Dagger, Hilt, Koin와 같은 DI 툴들을 선택해서 도입하게 되는데, 난 첫 DI 라이브러리로 Hilt를 사용했고 아직까지도 Hilt만 사용해오고 있다.
모든 디자인 패턴이 그렇듯, DI 패턴은 결합도 감소, 테스트 용이성 향상, 유지보수성 증가, 보일러플레이트 감소를 목적으로 사용된다. 내 생각에 DI 패턴만큼 테스트 용이성 향상과 결합도 감소에 효과적인 디자인 패턴은 없다.
게다가 안드로이드처럼 프레임워크 클래스들의 생명주기를 신경써야 하는 환경에서 Hilt나 Dagger를 사용한 DI 패턴은 더더욱 중요하다.
객체를 생성/파괴하는 로직을 라이브러리 레벨에서 처리해주기 때문에 객체의 생명주기와 관련한 휴먼 에러를 효과적으로 줄여주며, 의존성 그래프가 컴파일 타임에 검증되므로 런타임 안전성을 높일 수 있다.
또한 그로 인해 메모리 릭의 발생 가능성 또한 줄어들기 때문에 안드로이드 개발자라면 필수적으로 자세히 공부하고 효과적으로 사용할 줄 알아야 한다.
💡 Hilt
Hilt는 Dagger 프레임워크를 기반으로 만들어진 안드로이드 전용 DI 라이브러리이다.
Dagger는 개발자가 수동으로 설정해야하는 범위가 넓어 유연하지만 러닝커브가 가파르다는 단점이 있어서 Hilt는 이를 간소화시켜 제공함으로써 DI를 좀 더 쉽게 사용할 수 있게 해주는데, 이것이 내가 Hilt를 선택한 가장 주요한 이유이다.
당장 다음 프로젝트에 도입해야 하는 상황에서 Dagger의 러닝커브는 당시 1년차이던 나에겐 벽 같았다.
또 다른 DI 라이브러리인 Koin도 사용이 간편해서 도입을 고려했으나,
런타임에 리플렉션을 사용해서 의존성 주입을 처리하기 때문에 런타임 안정성이 낮고, 성능 저하가 발생할 수 있다는 단점 때문에 도입하지 않았다. 추가적으로 빌드 시 최적화 과정에서도 리플렉션 사용으로 인해 참조되는 코드의 최적화가 불가능하다는 단점도 존재한다.
이처럼 Hilt는 컴파일 타임에 의존성 그래프가 검증되며, 낮은 러닝커브로 사용이 편하다는 장점이 존재한다.
하지만 그로 인해 정확한 원리를 모른 채 관습적으로 코드를 작성하는 경향이 생길 수 있는데, 추후에 문제가 발생했을 때를 대비하고 근거 있는 코드를 작성하기 위해 내부적으로 어떻게 동작하는지 알아두는 것이 좋다.
1. Hilt의 구성요소들
동작 원리에 앞서 Hilt 사용에 핵심적인 두 가지 개념을 간단히 알아보자.
(1) Component

Hilt에는 안드로이드에서 사용하기 위해 미리 정의된 Component들이 존재하며, 이를 통해 안드로이드 구성요소들의 생명주기에 맞춰 의존성을 관리할 수 있다. Module들을 여러 종류의 Component에 설치할 수 있으며, 해당 모듈 내의 주입 함수들은 해당 Component의 생명주기에 따라서 의존성이 관리된다.
(2) Scope
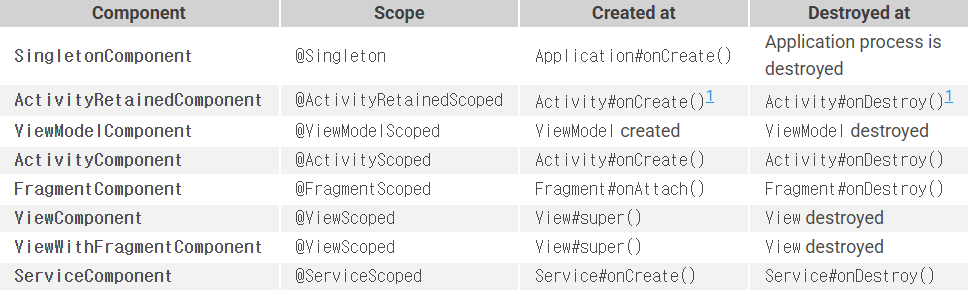
객체들의 수명주기는 Component의 생명주기에 따라 관리되지만, Scope는 좀 더 세부적인 제어를 위해 사용된다.
Component와 연결된 Scope를 사용하여 해당 Scope 내에서 동일한 인스턴스를 제공하도록 할 수 있다.
예를 들어 FragmentComponent에 설치된 모듈에서 FragmentScoped 어노테이션을 사용해서 의존성을 주입하면, 해당 Fragment의 생명주기 내에서 해당 객체는 동일한 인스턴스를 제공하게 된다.(Fragment 레벨에서 싱글톤 패턴을 사용한다고 생각하면 된다)
이처럼 Hilt는 Scope 어노테이션과 Provides/Binds 어노테이션을 사용해서 의존성 주입 메서드를 작성하고, 그 Module을 적절한 생명주기 관리를 위한 Component에 설치하여 의존성 그래프를 그림으로써 의존성이 주입된다.
여기까지는 너무나 당연하게 잘 알고 있던 구조인데, 한 뎁스 더 들어가서 내가 작성한 의존성 주입 메서드가 어떤 일련의 과정을 거쳐 의존성 그래프에 포함되는지 알아보자.
2. Hilt 의존성 주입 코드가 컴파일 동안 겪는 일들
@Module
@InstallIn(SingletonComponent::class)
class CpuModule {
@Provides
fun providesCpu(): Cpu = Cpu()
}
@Module
@InstallIn(SingletonComponent::class)
interface RamModule {
@Binds
fun bindsSamsungRam(
samsungRam: SamsungRam
): Ram
}
class Computer @Inject constructor(
private val cpu: Cpu,
private val ram: Ram,
)
@AndroidEntryPoint
class MainActivity : AppCompatActivity() {
@Inject
lateinit var computer: Computer
}
위 코드는 예시를 위한 간단한 Hilt DI 코드이다.
이를 그림으로 표현하면 아래와 같다.
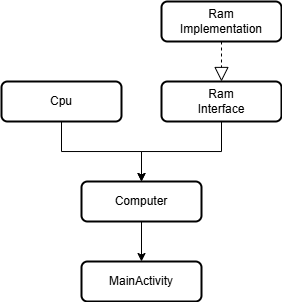
Provides/Binds 어노테이션을 사용해서 Cpu, Ram 인스턴스를 제공하고, Inject 어노테이션을 사용해서 Computer 클래스에 생성자 주입으로 Cpu, Ram 인스턴스를 주입한다.
그리고 마지막으로 실제 Computer 인스턴스가 사용되는 안드로이드 프레임워크 클래스인 MainActivity 클래스에 필드 주입으로 Computer 인스턴스를 주입하게 되는 구조이다.
위 코드에서는 의존성 주입과 관련된 구체화된 코드를 찾아볼 수 없는데, Hilt는 어떻게 어노테이션을 작성하는 것 만으로 의존성 주입을 처리할 수 있을까?
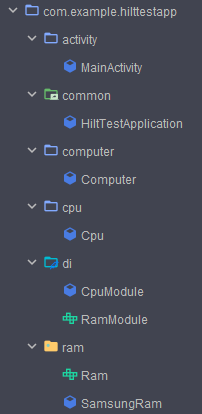
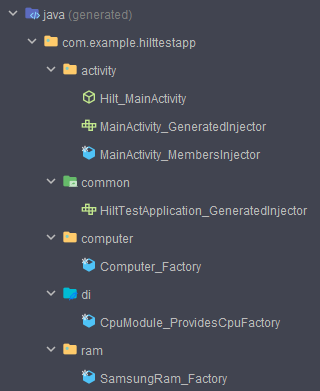
그건 Hilt 프로세서가 어노테이션을 해석해서 의존성 주입에 필요한 실질적인 클래스들을 생성해주기 때문이다.
위처럼 코틀린 코드들이 의존성 주입에 사용되는 자바 코드로 변환 및 생성되는 것을 볼 수 있다.
하지만 이런 과정 또한 Hilt 프로세서가 바로 의존성 그래프를 완성하는 방식으로 동작하지 않는다.
생성된 위 코드는 Hilt 프로세서가 생성한게 아니라, Dagger 프로세서가 생성한 코드이기 때문이다.(최종 코드)
아래 코드가 Hilt 프로세서가 생성한 클래스인데, 여전히 Component, Singleton 등의 어노테이션이 포함되어 있는 것을 볼 수 있다.
@Generated("dagger.hilt.processor.internal.root.RootProcessor")
public final class HiltTestApplication_HiltComponents {
private HiltTestApplication_HiltComponents() {
}
. . .
@Component(
modules = {
ApplicationContextModule.class,
ComputerModule.class,
CpuModule.class,
ActivityRetainedCBuilderModule.class,
ServiceCBuilderModule.class,
HiltWrapper_FragmentGetContextFix_FragmentGetContextFixModule.class,
RamModule.class
}
)
@Singleton
public abstract static class SingletonC implements HiltTestApplication_GeneratedInjector,
FragmentGetContextFix.FragmentGetContextFixEntryPoint,
HiltWrapper_ActivityRetainedComponentManager_ActivityRetainedComponentBuilderEntryPoint,
ServiceComponentManager.ServiceComponentBuilderEntryPoint,
SingletonComponent,
GeneratedComponent {
}
. . .
}
Hilt 프로세서가 컴파일 타임에 어노테이션을 해석하고 의존성 주입 코드를 생성하는 줄 알았는데, Hilt 프로세서가 생성한 코드에 왜 여전히 어노테이션이 남아있는 걸까?
✨ Hilt의 내부 동작 원리
그 이유는 Hilt라는 라이브러리가 탄생하게 된 배경을 통해 알 수 있다.
앞서 글 초반에 Hilt는 Dagger의 높은 러닝커브와 번거로운 설정을 간소화시킴으로써 DI를 좀 더 쉽게 해주는 라이브러리라고 설명했다.
그렇기 때문에 Hilt는 코드를 바로 실질적인 의존성 주입 코드로 변환하는 것이 아니라 Dagger 코드로 변환한 후 Dagger 프로세서를 통해 의존성 주입 코드를 생성함으로써 의존성 그래프를 완성하는 구조로 동작한다.
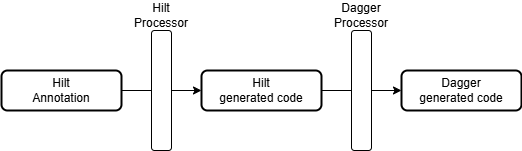
Hilt 프로세서가 생성한 코드는 Dagger가 이해할 수 있는 중간 코드이며, 그 코드를 Dagger 프로세서가 다시 해석해서 최종 산출 코드로 변환하여 DI 그래프를 구성하게 된다. 이런 구조 덕분에 우리는 Dagger 사용시에 해야 할 복잡하고 어려운 설정을 할 필요 없이 간단한 코드 작성만으로 의존성 주입을 할 수 있는 것이다.
❓Binds와 Provides의 동작 원리는 어떻게 다를까?
Binds는 인터페이스와 구현체간의 관계를 매핑하기 위해 사용되는 Hilt 어노테이션이다.
사실 처음 Hilt를 사용하던 시절에는 클린 아키텍처 또한 도입하지 않았던 터라, Provides 만 사용해서 모든 DI를 처리했던 기억이 난다.(추상화를 적극 활용하지 않는 구조였다)
그 때 Provides를 사용한 DI는 Module 클래스의 주입 함수들에 객체 생성 로직이 "의존성 주입" 역할의 코드와 합쳐져 있어, 책임의 범위가 애매하다는 느낌을 받았었다.
이처럼 Provides 어노테이션은 구체적인 객체 생성 로직을 작성하는 반면, Binds 어노테이션은 실제 인스턴스 생성을 포함하지 않고 "인터페이스와 구현체 간의 관계를 매핑"한 후 객체 사용 시점에 해당 의존성을 주입하게 된다.
✨ 생성되는 코드 관점
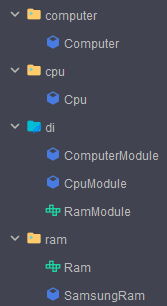
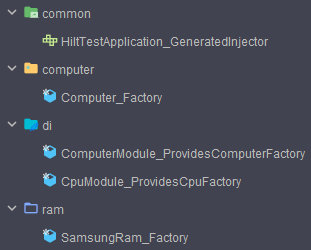
Binds는 객체 생성 로직을 포함하지 않고, 객체간의 관계를 매핑하는 방식으로 동작한다. Provides와 동작 방식이 다르므로 아래 이미지처럼 생성되는 클래스의 위치도 다른 것을 볼 수 있다.
컴파일 전에 모든 Module들은 di 패키지에 속해있지만, Provides를 사용하는 Module 클래스는 해당 디렉토리 내부에 컴파일되어 생성되고,
Binds를 사용한 Module 인터페이스는 매핑만을 수행하므로 해당 객체들이 포함된 디렉토리 내부에 생성되는 것을 볼 수 있다.
(1) Provides의 경우
Provides 어노테이션을 사용해서 주입되는 객체는 Factory 클래스 내부에서 providesXXX 메서드를 통해 객체를 생성하는 방식으로 동작한다.
생성자에서 CpuModule을 초기화한 후, providesCpu 메서드에 모듈 인스턴스를 아규먼트로 전달하는 것을 볼 수 있다.
이 providesCpu 메서드가 우리가 CpuModule에 작성한 Cpu 의존성 주입 메서드를 호출하게 된다.
// @Provides 사용 시 생성되는 Factory 클래스. Dagger 프로세서가 생성한 최종 코드이다
public final class CpuModule_ProvidesCpuFactory implements Factory<Cpu> {
private final CpuModule module;
public CpuModule_ProvidesCpuFactory(CpuModule module) {
this.module = module;
}
@Override
public Cpu get() {
return providesCpu(module);
}
public static CpuModule_ProvidesCpuFactory create(CpuModule module) {
return new CpuModule_ProvidesCpuFactory(module);
}
public static Cpu providesCpu(CpuModule instance) {
return Preconditions.checkNotNullFromProvides(instance.providesCpu());
}
}
(2) Binds의 경우
Binds의 경우에는 내부적으로 조금 다르게 동작하는 것을 볼 수 있다.
생성된 Factory 클래스가 RamModule에 대한 참조를 가지지 않고, 바로 new SansungRam() 메서드를 호출해 객체를 생성하고 있다.
이건 Binds가 Provides와는 달리, Inject 어노테이션을 사용한 생성자를 통해 구현체를 제공하기 때문이다.(Binds 어노테이션을 사용한 주입 메서드에는 객체 생성 로직이 포함되지 않으므로)
Hilt 프로세서는 Inject 어노테이션을 통해 해당 클래스가 구현체임을 확인한다. 이 덕분에 정확히 타입 매핑만 수행하는 것이다.
// Binds 사용시 생성되는 Factory 클래스
public final class SamsungRam_Factory implements Factory<SamsungRam> {
@Override
public SamsungRam get() {
return newInstance();
}
public static SamsungRam_Factory create() {
return InstanceHolder.INSTANCE;
}
public static SamsungRam newInstance() {
return new SamsungRam();
}
private static final class InstanceHolder {
private static final SamsungRam_Factory INSTANCE = new SamsungRam_Factory();
}
}
✨ 런타임 성능 관점
(1) Binds
객체 생성 로직을 포함하지 않고 런타임에 매핑만 처리되어 상대적으로 런타임 오버헤드가 낮고, 의존성 주입 로직과 객체 생성 로직이 분리되어 코드가 간결해지고 책임이 명확해 진다.
클린 아키텍처처럼 추상화가 많은 구조에서 Binds를 사용한 주입은 컴파일 타임에 잘못된 매핑 관계나 매핑 누락을 찾을 수 있어 런타임 안정성을 높일 수 있다는 장점 또한 존재한다.
(2) Provides
Binds 어노테이션을 사용한 주입 메서드는 매핑 시에 구현체 생성 로직을 제공하기 위해 Inject 어노테이션과 함께 사용되는 반면, Provides 사용시에는 주입 함수에서 구현체를 직접적으로 제공하기 때문에 Inject 어노테이션이 필요하지 않다.
복잡한 객체 생성 로직을 포함할 수 있고, 이를 통해 의존성을 주입할 수 있지만
그 과정에서 module 클래스를 참조하여 주입 메서드를 호출하므로 메서드 호출 스택이 한 번 더 생겨서 Binds를 사용하는 방식에 비해 상대적으로 런타임 오버헤드가 높다는 단점이 있다.
최근 들어 포스팅 방식을 바꾸면서 느낀 점인데, 컴파일러 관련 정보나 라이브러리 내부 동작 원리에 대해 공부하는 게 전체적인 학습 깊이에 엄청나게 큰 영향을 미치는 것 같다.
매번 포스팅을 작성하기 위해 8~10시간 정도 내부 코드, , 공식 문서를 뒤지면서 공부하고 있는데, 예전처럼 면접 질문들을 형식적으로 외우는 것보다 훨씬 깊이 이해도 잘 되고 머리에 오래 남는 것 같다.
'개발 > Android' 카테고리의 다른 글
| [안드로이드] Context와 메모리 누수 (0) | 2025.04.07 |
|---|---|
| [안드로이드] 난독화와 R8 컴파일러 (0) | 2025.03.17 |
| [안드로이드] Vector Drawable 변환 과정과 Bitmap(feat.dp를 사용하면 모든 화면에서 동일하게 보일까?) (0) | 2025.03.06 |
| [안드로이드] 쉘 스크립트로 이미지를 dpi 폴더에 분류하기(feat.해상도 대응) (0) | 2025.03.04 |
| [안드로이드] ART의 GC는 어떻게 동작할까(feat.Dalvik) (0) | 2025.02.17 |
💡DI 패턴을 사용하는 이유
안드로이드 진영에서 DI 패턴은 필수적으로 사용되는 디자인 패턴 중 하나이다.
여기서 개발자들은 Dagger, Hilt, Koin와 같은 DI 툴들을 선택해서 도입하게 되는데, 난 첫 DI 라이브러리로 Hilt를 사용했고 아직까지도 Hilt만 사용해오고 있다.
모든 디자인 패턴이 그렇듯, DI 패턴은 결합도 감소, 테스트 용이성 향상, 유지보수성 증가, 보일러플레이트 감소를 목적으로 사용된다. 내 생각에 DI 패턴만큼 테스트 용이성 향상과 결합도 감소에 효과적인 디자인 패턴은 없다.
게다가 안드로이드처럼 프레임워크 클래스들의 생명주기를 신경써야 하는 환경에서 Hilt나 Dagger를 사용한 DI 패턴은 더더욱 중요하다.
객체를 생성/파괴하는 로직을 라이브러리 레벨에서 처리해주기 때문에 객체의 생명주기와 관련한 휴먼 에러를 효과적으로 줄여주며, 의존성 그래프가 컴파일 타임에 검증되므로 런타임 안전성을 높일 수 있다.
또한 그로 인해 메모리 릭의 발생 가능성 또한 줄어들기 때문에 안드로이드 개발자라면 필수적으로 자세히 공부하고 효과적으로 사용할 줄 알아야 한다.
💡 Hilt
Hilt는 Dagger 프레임워크를 기반으로 만들어진 안드로이드 전용 DI 라이브러리이다.
Dagger는 개발자가 수동으로 설정해야하는 범위가 넓어 유연하지만 러닝커브가 가파르다는 단점이 있어서 Hilt는 이를 간소화시켜 제공함으로써 DI를 좀 더 쉽게 사용할 수 있게 해주는데, 이것이 내가 Hilt를 선택한 가장 주요한 이유이다.
당장 다음 프로젝트에 도입해야 하는 상황에서 Dagger의 러닝커브는 당시 1년차이던 나에겐 벽 같았다.
또 다른 DI 라이브러리인 Koin도 사용이 간편해서 도입을 고려했으나,
런타임에 리플렉션을 사용해서 의존성 주입을 처리하기 때문에 런타임 안정성이 낮고, 성능 저하가 발생할 수 있다는 단점 때문에 도입하지 않았다. 추가적으로 빌드 시 최적화 과정에서도 리플렉션 사용으로 인해 참조되는 코드의 최적화가 불가능하다는 단점도 존재한다.
이처럼 Hilt는 컴파일 타임에 의존성 그래프가 검증되며, 낮은 러닝커브로 사용이 편하다는 장점이 존재한다.
하지만 그로 인해 정확한 원리를 모른 채 관습적으로 코드를 작성하는 경향이 생길 수 있는데, 추후에 문제가 발생했을 때를 대비하고 근거 있는 코드를 작성하기 위해 내부적으로 어떻게 동작하는지 알아두는 것이 좋다.
1. Hilt의 구성요소들
동작 원리에 앞서 Hilt 사용에 핵심적인 두 가지 개념을 간단히 알아보자.
(1) Component
Hilt에는 안드로이드에서 사용하기 위해 미리 정의된 Component들이 존재하며, 이를 통해 안드로이드 구성요소들의 생명주기에 맞춰 의존성을 관리할 수 있다. Module들을 여러 종류의 Component에 설치할 수 있으며, 해당 모듈 내의 주입 함수들은 해당 Component의 생명주기에 따라서 의존성이 관리된다.
(2) Scope
객체들의 수명주기는 Component의 생명주기에 따라 관리되지만, Scope는 좀 더 세부적인 제어를 위해 사용된다.
Component와 연결된 Scope를 사용하여 해당 Scope 내에서 동일한 인스턴스를 제공하도록 할 수 있다.
예를 들어 FragmentComponent에 설치된 모듈에서 FragmentScoped 어노테이션을 사용해서 의존성을 주입하면, 해당 Fragment의 생명주기 내에서 해당 객체는 동일한 인스턴스를 제공하게 된다.(Fragment 레벨에서 싱글톤 패턴을 사용한다고 생각하면 된다)
이처럼 Hilt는 Scope 어노테이션과 Provides/Binds 어노테이션을 사용해서 의존성 주입 메서드를 작성하고, 그 Module을 적절한 생명주기 관리를 위한 Component에 설치하여 의존성 그래프를 그림으로써 의존성이 주입된다.
여기까지는 너무나 당연하게 잘 알고 있던 구조인데, 한 뎁스 더 들어가서 내가 작성한 의존성 주입 메서드가 어떤 일련의 과정을 거쳐 의존성 그래프에 포함되는지 알아보자.
2. Hilt 의존성 주입 코드가 컴파일 동안 겪는 일들
@Module
@InstallIn(SingletonComponent::class)
class CpuModule {
@Provides
fun providesCpu(): Cpu = Cpu()
}
@Module
@InstallIn(SingletonComponent::class)
interface RamModule {
@Binds
fun bindsSamsungRam(
samsungRam: SamsungRam
): Ram
}
class Computer @Inject constructor(
private val cpu: Cpu,
private val ram: Ram,
)
@AndroidEntryPoint
class MainActivity : AppCompatActivity() {
@Inject
lateinit var computer: Computer
}
위 코드는 예시를 위한 간단한 Hilt DI 코드이다.
이를 그림으로 표현하면 아래와 같다.
Provides/Binds 어노테이션을 사용해서 Cpu, Ram 인스턴스를 제공하고, Inject 어노테이션을 사용해서 Computer 클래스에 생성자 주입으로 Cpu, Ram 인스턴스를 주입한다.
그리고 마지막으로 실제 Computer 인스턴스가 사용되는 안드로이드 프레임워크 클래스인 MainActivity 클래스에 필드 주입으로 Computer 인스턴스를 주입하게 되는 구조이다.
위 코드에서는 의존성 주입과 관련된 구체화된 코드를 찾아볼 수 없는데, Hilt는 어떻게 어노테이션을 작성하는 것 만으로 의존성 주입을 처리할 수 있을까?
그건 Hilt 프로세서가 어노테이션을 해석해서 의존성 주입에 필요한 실질적인 클래스들을 생성해주기 때문이다.
위처럼 코틀린 코드들이 의존성 주입에 사용되는 자바 코드로 변환 및 생성되는 것을 볼 수 있다.
하지만 이런 과정 또한 Hilt 프로세서가 바로 의존성 그래프를 완성하는 방식으로 동작하지 않는다.
생성된 위 코드는 Hilt 프로세서가 생성한게 아니라, Dagger 프로세서가 생성한 코드이기 때문이다.(최종 코드)
아래 코드가 Hilt 프로세서가 생성한 클래스인데, 여전히 Component, Singleton 등의 어노테이션이 포함되어 있는 것을 볼 수 있다.
@Generated("dagger.hilt.processor.internal.root.RootProcessor")
public final class HiltTestApplication_HiltComponents {
private HiltTestApplication_HiltComponents() {
}
. . .
@Component(
modules = {
ApplicationContextModule.class,
ComputerModule.class,
CpuModule.class,
ActivityRetainedCBuilderModule.class,
ServiceCBuilderModule.class,
HiltWrapper_FragmentGetContextFix_FragmentGetContextFixModule.class,
RamModule.class
}
)
@Singleton
public abstract static class SingletonC implements HiltTestApplication_GeneratedInjector,
FragmentGetContextFix.FragmentGetContextFixEntryPoint,
HiltWrapper_ActivityRetainedComponentManager_ActivityRetainedComponentBuilderEntryPoint,
ServiceComponentManager.ServiceComponentBuilderEntryPoint,
SingletonComponent,
GeneratedComponent {
}
. . .
}
Hilt 프로세서가 컴파일 타임에 어노테이션을 해석하고 의존성 주입 코드를 생성하는 줄 알았는데, Hilt 프로세서가 생성한 코드에 왜 여전히 어노테이션이 남아있는 걸까?
✨ Hilt의 내부 동작 원리
그 이유는 Hilt라는 라이브러리가 탄생하게 된 배경을 통해 알 수 있다.
앞서 글 초반에 Hilt는 Dagger의 높은 러닝커브와 번거로운 설정을 간소화시킴으로써 DI를 좀 더 쉽게 해주는 라이브러리라고 설명했다.
그렇기 때문에 Hilt는 코드를 바로 실질적인 의존성 주입 코드로 변환하는 것이 아니라 Dagger 코드로 변환한 후 Dagger 프로세서를 통해 의존성 주입 코드를 생성함으로써 의존성 그래프를 완성하는 구조로 동작한다.
Hilt 프로세서가 생성한 코드는 Dagger가 이해할 수 있는 중간 코드이며, 그 코드를 Dagger 프로세서가 다시 해석해서 최종 산출 코드로 변환하여 DI 그래프를 구성하게 된다. 이런 구조 덕분에 우리는 Dagger 사용시에 해야 할 복잡하고 어려운 설정을 할 필요 없이 간단한 코드 작성만으로 의존성 주입을 할 수 있는 것이다.
❓Binds와 Provides의 동작 원리는 어떻게 다를까?
Binds는 인터페이스와 구현체간의 관계를 매핑하기 위해 사용되는 Hilt 어노테이션이다.
사실 처음 Hilt를 사용하던 시절에는 클린 아키텍처 또한 도입하지 않았던 터라, Provides 만 사용해서 모든 DI를 처리했던 기억이 난다.(추상화를 적극 활용하지 않는 구조였다)
그 때 Provides를 사용한 DI는 Module 클래스의 주입 함수들에 객체 생성 로직이 "의존성 주입" 역할의 코드와 합쳐져 있어, 책임의 범위가 애매하다는 느낌을 받았었다.
이처럼 Provides 어노테이션은 구체적인 객체 생성 로직을 작성하는 반면, Binds 어노테이션은 실제 인스턴스 생성을 포함하지 않고 "인터페이스와 구현체 간의 관계를 매핑"한 후 객체 사용 시점에 해당 의존성을 주입하게 된다.
✨ 생성되는 코드 관점
Binds는 객체 생성 로직을 포함하지 않고, 객체간의 관계를 매핑하는 방식으로 동작한다. Provides와 동작 방식이 다르므로 아래 이미지처럼 생성되는 클래스의 위치도 다른 것을 볼 수 있다.
컴파일 전에 모든 Module들은 di 패키지에 속해있지만, Provides를 사용하는 Module 클래스는 해당 디렉토리 내부에 컴파일되어 생성되고,
Binds를 사용한 Module 인터페이스는 매핑만을 수행하므로 해당 객체들이 포함된 디렉토리 내부에 생성되는 것을 볼 수 있다.
(1) Provides의 경우
Provides 어노테이션을 사용해서 주입되는 객체는 Factory 클래스 내부에서 providesXXX 메서드를 통해 객체를 생성하는 방식으로 동작한다.
생성자에서 CpuModule을 초기화한 후, providesCpu 메서드에 모듈 인스턴스를 아규먼트로 전달하는 것을 볼 수 있다.
이 providesCpu 메서드가 우리가 CpuModule에 작성한 Cpu 의존성 주입 메서드를 호출하게 된다.
// @Provides 사용 시 생성되는 Factory 클래스. Dagger 프로세서가 생성한 최종 코드이다
public final class CpuModule_ProvidesCpuFactory implements Factory<Cpu> {
private final CpuModule module;
public CpuModule_ProvidesCpuFactory(CpuModule module) {
this.module = module;
}
@Override
public Cpu get() {
return providesCpu(module);
}
public static CpuModule_ProvidesCpuFactory create(CpuModule module) {
return new CpuModule_ProvidesCpuFactory(module);
}
public static Cpu providesCpu(CpuModule instance) {
return Preconditions.checkNotNullFromProvides(instance.providesCpu());
}
}
(2) Binds의 경우
Binds의 경우에는 내부적으로 조금 다르게 동작하는 것을 볼 수 있다.
생성된 Factory 클래스가 RamModule에 대한 참조를 가지지 않고, 바로 new SansungRam() 메서드를 호출해 객체를 생성하고 있다.
이건 Binds가 Provides와는 달리, Inject 어노테이션을 사용한 생성자를 통해 구현체를 제공하기 때문이다.(Binds 어노테이션을 사용한 주입 메서드에는 객체 생성 로직이 포함되지 않으므로)
Hilt 프로세서는 Inject 어노테이션을 통해 해당 클래스가 구현체임을 확인한다. 이 덕분에 정확히 타입 매핑만 수행하는 것이다.
// Binds 사용시 생성되는 Factory 클래스
public final class SamsungRam_Factory implements Factory<SamsungRam> {
@Override
public SamsungRam get() {
return newInstance();
}
public static SamsungRam_Factory create() {
return InstanceHolder.INSTANCE;
}
public static SamsungRam newInstance() {
return new SamsungRam();
}
private static final class InstanceHolder {
private static final SamsungRam_Factory INSTANCE = new SamsungRam_Factory();
}
}
✨ 런타임 성능 관점
(1) Binds
객체 생성 로직을 포함하지 않고 런타임에 매핑만 처리되어 상대적으로 런타임 오버헤드가 낮고, 의존성 주입 로직과 객체 생성 로직이 분리되어 코드가 간결해지고 책임이 명확해 진다.
클린 아키텍처처럼 추상화가 많은 구조에서 Binds를 사용한 주입은 컴파일 타임에 잘못된 매핑 관계나 매핑 누락을 찾을 수 있어 런타임 안정성을 높일 수 있다는 장점 또한 존재한다.
(2) Provides
Binds 어노테이션을 사용한 주입 메서드는 매핑 시에 구현체 생성 로직을 제공하기 위해 Inject 어노테이션과 함께 사용되는 반면, Provides 사용시에는 주입 함수에서 구현체를 직접적으로 제공하기 때문에 Inject 어노테이션이 필요하지 않다.
복잡한 객체 생성 로직을 포함할 수 있고, 이를 통해 의존성을 주입할 수 있지만
그 과정에서 module 클래스를 참조하여 주입 메서드를 호출하므로 메서드 호출 스택이 한 번 더 생겨서 Binds를 사용하는 방식에 비해 상대적으로 런타임 오버헤드가 높다는 단점이 있다.
최근 들어 포스팅 방식을 바꾸면서 느낀 점인데, 컴파일러 관련 정보나 라이브러리 내부 동작 원리에 대해 공부하는 게 전체적인 학습 깊이에 엄청나게 큰 영향을 미치는 것 같다.
매번 포스팅을 작성하기 위해 8~10시간 정도 내부 코드, , 공식 문서를 뒤지면서 공부하고 있는데, 예전처럼 면접 질문들을 형식적으로 외우는 것보다 훨씬 깊이 이해도 잘 되고 머리에 오래 남는 것 같다.
'개발 > Android' 카테고리의 다른 글
| [안드로이드] Context와 메모리 누수 (0) | 2025.04.07 |
|---|---|
| [안드로이드] 난독화와 R8 컴파일러 (0) | 2025.03.17 |
| [안드로이드] Vector Drawable 변환 과정과 Bitmap(feat.dp를 사용하면 모든 화면에서 동일하게 보일까?) (0) | 2025.03.06 |
| [안드로이드] 쉘 스크립트로 이미지를 dpi 폴더에 분류하기(feat.해상도 대응) (0) | 2025.03.04 |
| [안드로이드] ART의 GC는 어떻게 동작할까(feat.Dalvik) (0) | 2025.02.17 |